Train, select and serve a model
The title already summarizes where this example is all about. We will show how you can:
- train multiple models
- get run metrics to select the best model
- use the best model to serve a prediction
- work with input data for jobs
In this project, we train an AI model that you can use to predict the quality of a wine. Besides training the model, we also add a job to show how to serve a model using AskAnna. In this example, serving the model means you can predict the wine quality of a new wine using the trained model.
For training, we use an Elastic Net model. The dataset used is Wine Quality. The source code can be found on GitLab. Inspiration for this example came from MLFlow and UbiOps.
If you want to run the models yourself, you need:
- an AskAnna account (you can sign up for free)
- Python > 3.6
- install the AskAnna CLI and login
First, we will give you a quick tour of running this example. After the quick tour, we will tell more about what happened and share more details regarding this project.
Quick tour
In your terminal, run the following to create a new project using the Demo train, select and serve model template:
askanna create --template https://gitlab.com/askanna/demo/demo-train-select-serve-model.git --push
You only have to specify the project name. We named it Train, select and serve. If you confirm, the AskAnna CLI will set up a new project.
Now you can run the job that starts different train runs and select the best model:
askanna run --data-file input/dummy-select-model.json select-best-model
To check the status of the run, go to https://beta.askanna.eu and select the project you just created. In this project, open the jobs tab. Click on of the job select-best-model. Next, click on the run and check the status.
If the job select-best-model is finished, you can also run the serve job. In your terminal, enter the command:
askanna run --data-file input/dummy-serve-single.json serve-model
Go back to the project in the browser, and open the run of the job serve-model. When the run finished, you can find the prediction for the quality of the wine in the RESULT tab.
The above is an abridged version of how you can train, select and serve models in AskAnna. Next, we will deep dive into the different steps to share more background about what just happened.
What happened in the quick tour?
Create new project
In your terminal, you run the AskAnna command to create a new project using one of our demo projects:
askanna create --template https://gitlab.com/askanna/demo/demo-train-select-serve-model.git --push
After you confirmed that you want to create the project, the next happened:
- a new project in AskAnna was created
- a new local directory for the project was created based on the project name
- the project files were copied from the project template in the local directory
- pushed a version of the project files to AskAnna
Read more about creating projects and project templates
Run jobs
In this project, you can run three different jobs. Here we show per job more about running them in AskAnna. In the section About the project code we tell more about the code and the askanna.yml configuration.
Select best model
In the quick tour, we showed how you run the job using the command line:
askanna run --data-file input/dummy-select-model.json select-best-model
Running this command will start a run with the JSON file as the data payload. If you want to try other parameters, refer to another JSON file using the same parameter structure.
You can also start the run using the web interface. When you created the project and pushed the code:
- go to the project page
- open the
JOBStab - click on the job
select-best-model - scroll down and start a new run
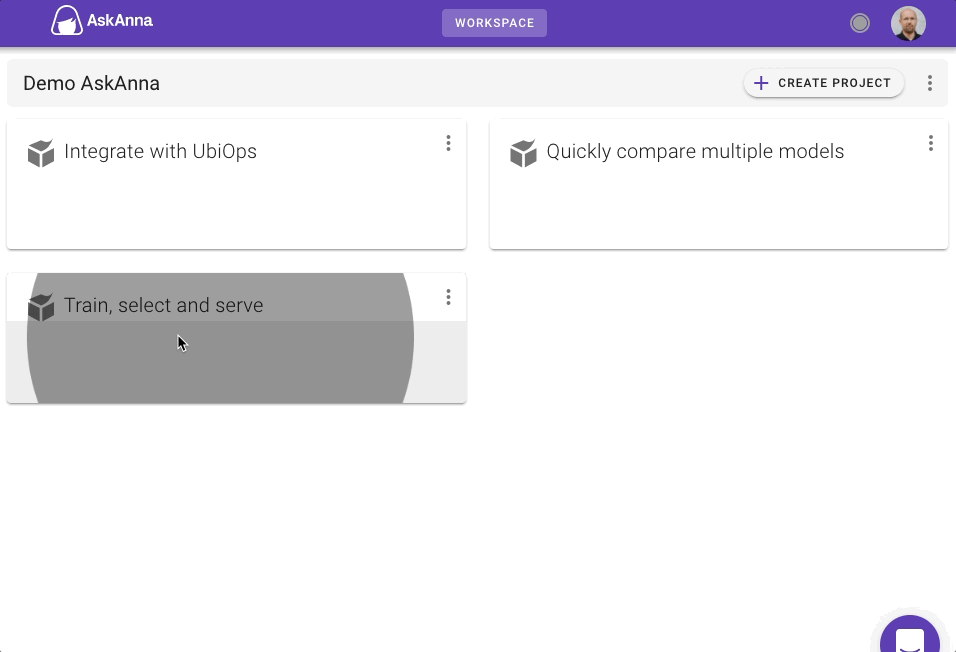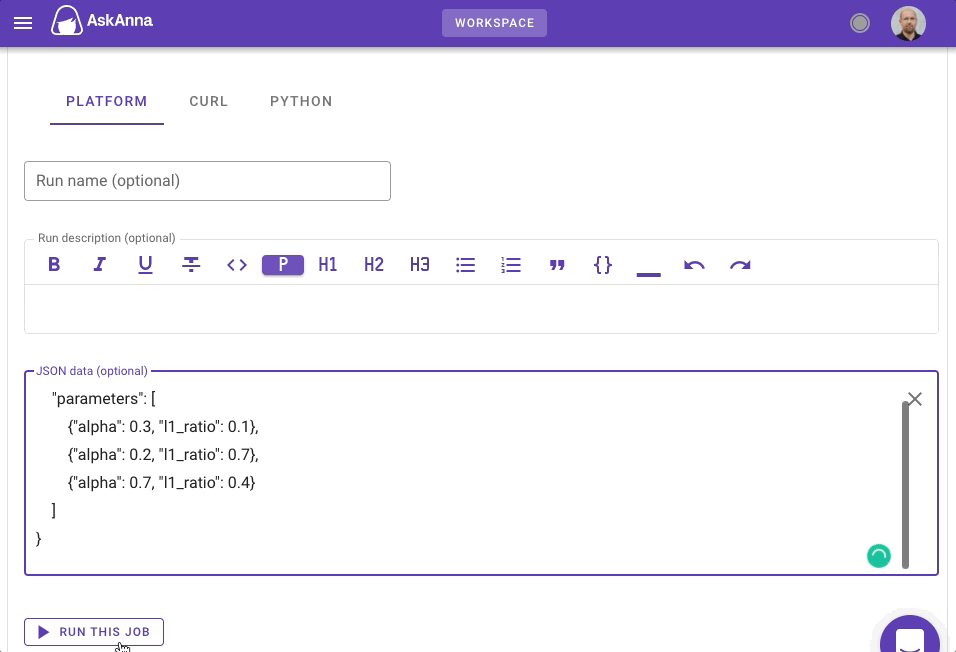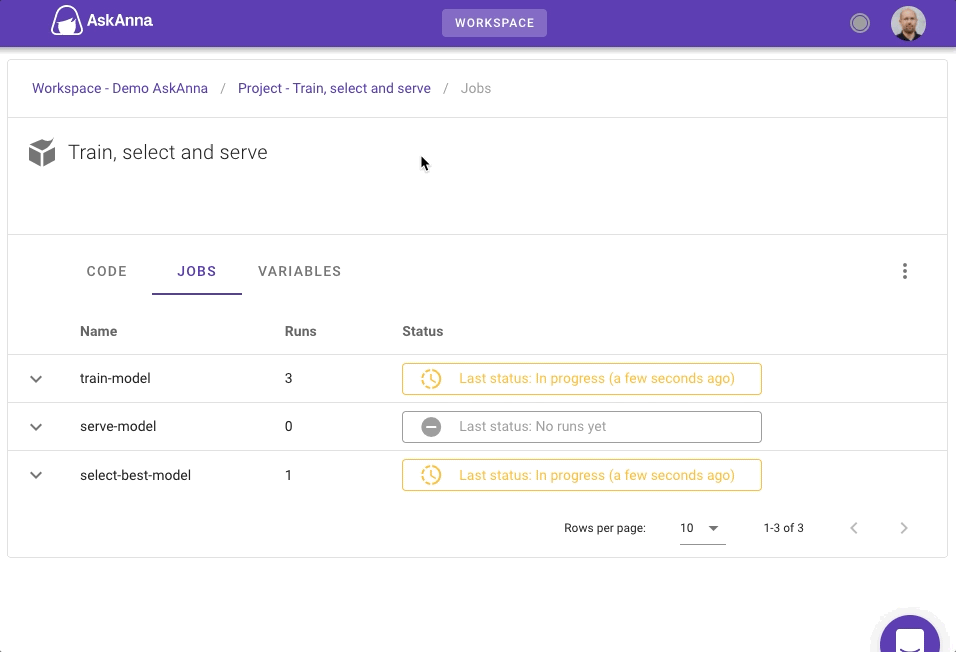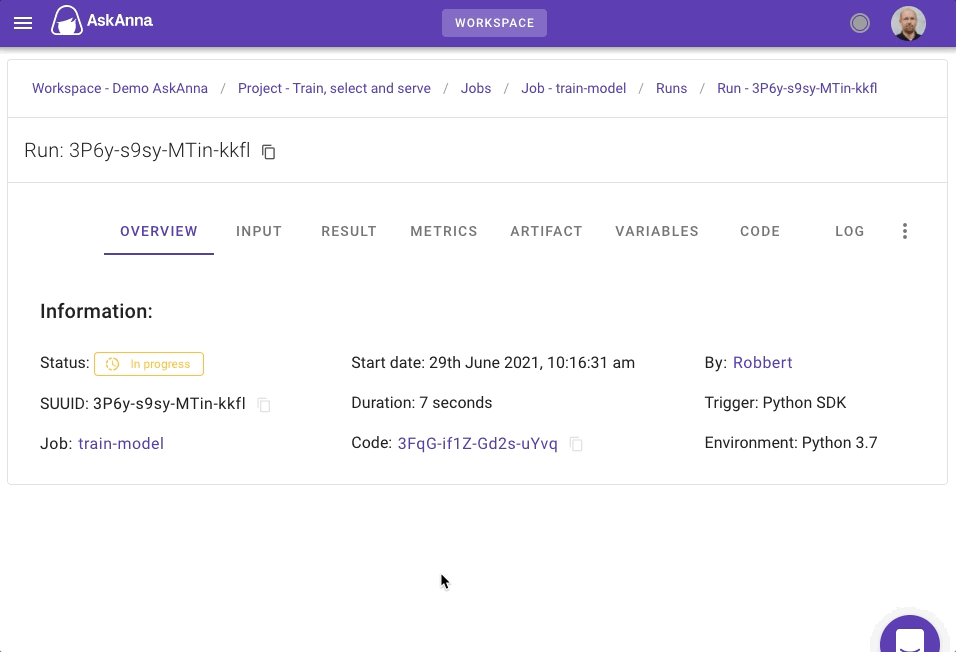
You could add an optional JSON payload. In the next image we used the payload:
{
"parameters": [
{"alpha": 0.3, "l1_ratio": 0.1},
{"alpha": 0.2, "l1_ratio": 0.7},
{"alpha": 0.7, "l1_ratio": 0.4}
]
}
When you start a new run, AskAnna will spin up an environment that also starts the configured train jobs. It can take a couple of minutes before the run finishes. When all jobs are finished, you can see which model is selected by checking the metrics. See also review the select best model run.
Train model
If you want to train a model with parameters alpha and l1_ratio, you can use the next command as the base and change the paramater values:
askanna run --data '{"alpha": 0.7, "l1_ratio": 0.4}' train-model
You can use the JSON data also to start the job via the web interface.
{
"alpha": 0.7,
"l1_ratio": 0.4
}
Serve model
When at least one select-best-model run is finished, you can serve a result using the AskAnna CLI:
askanna run --data-file input/dummy-serve-single.json serve-model
Besides the option to start the run via the web interface, on the job page you can also find information on how to start this job using the AskAnna API. The API makes it easy to integrate serving a model with an existing application that wants to consume the result of a job.
Review runs
Train run
You can find the trained model on the RESULT tab in the web interface for each train run. Here you can also download the trained model. Also, you can review the metrics to see the performance of the model:
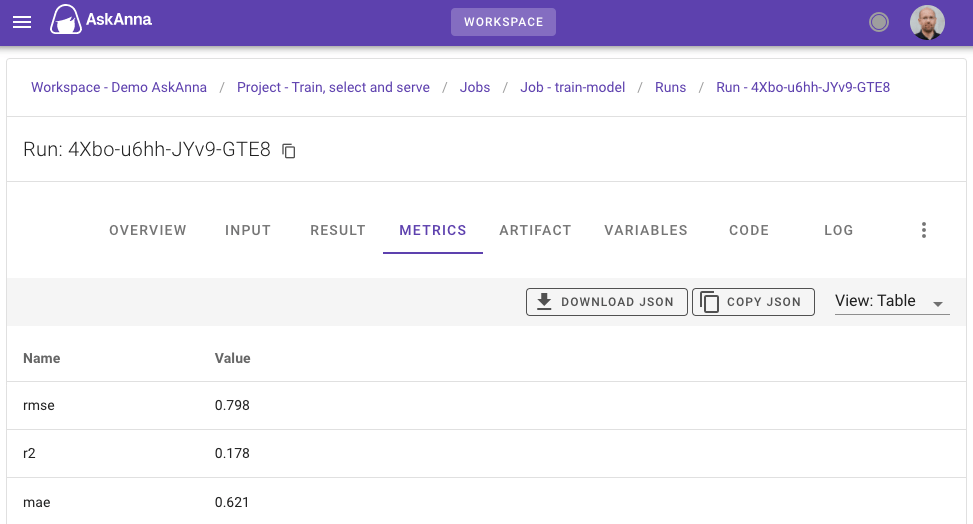
Or variables to check the parameters used:
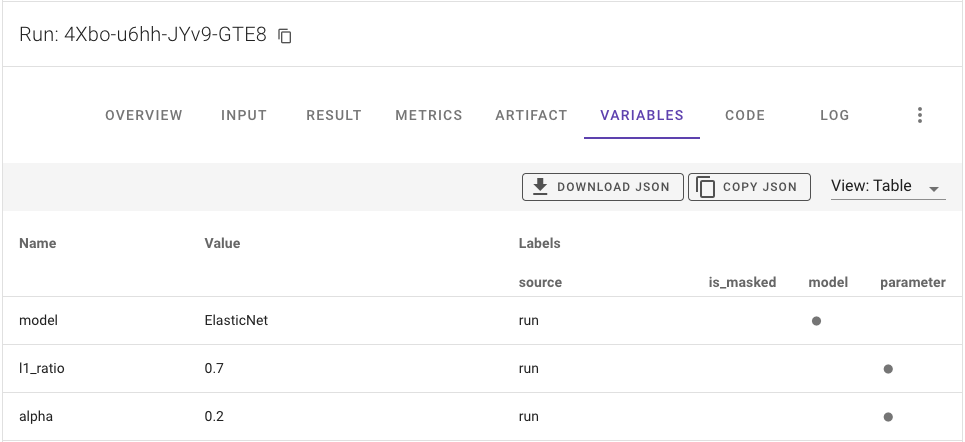
Select best model run
On the run page of this job, you can find information about the selected best model in the metrics:
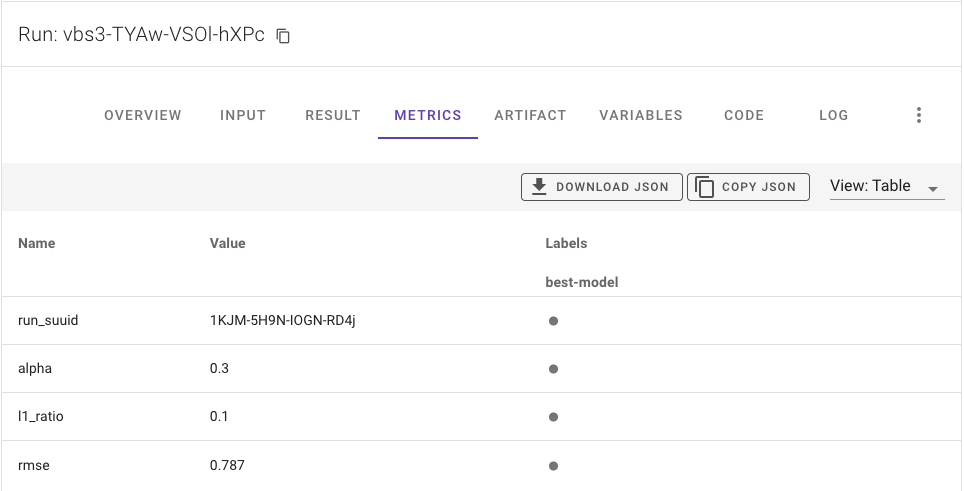
If you want to see the train jobs used to select the best model, you can find this information in the VARIABLES tab:
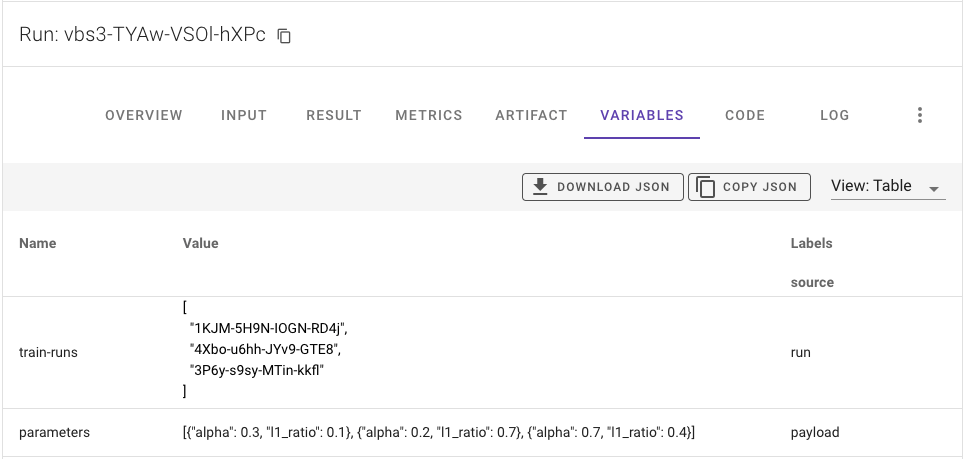
Serve model run
The most important information for the job serve-model is the result that contains per wine a prediction of the quality. You can review these predictions on the tab RESULT. Here you can also download the CSV file.
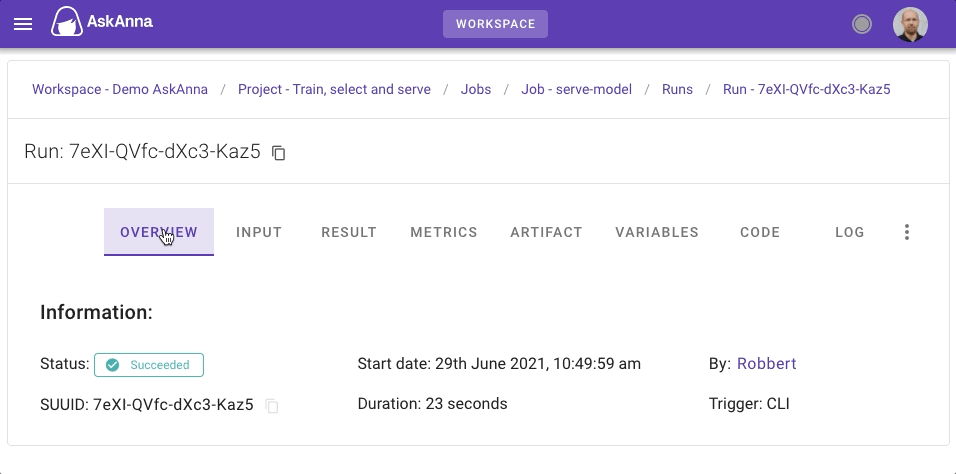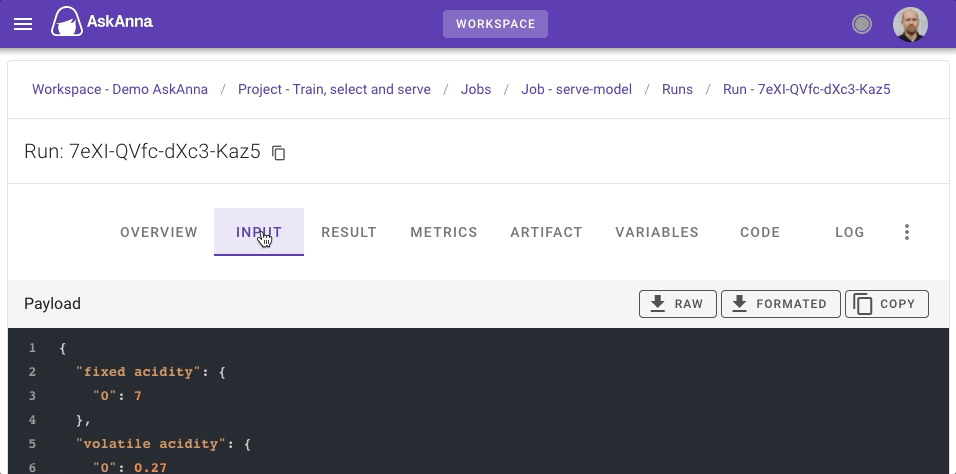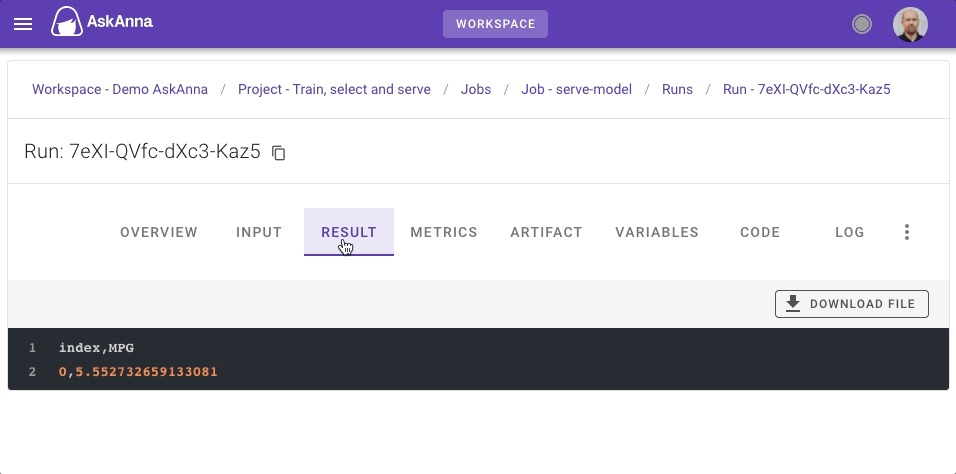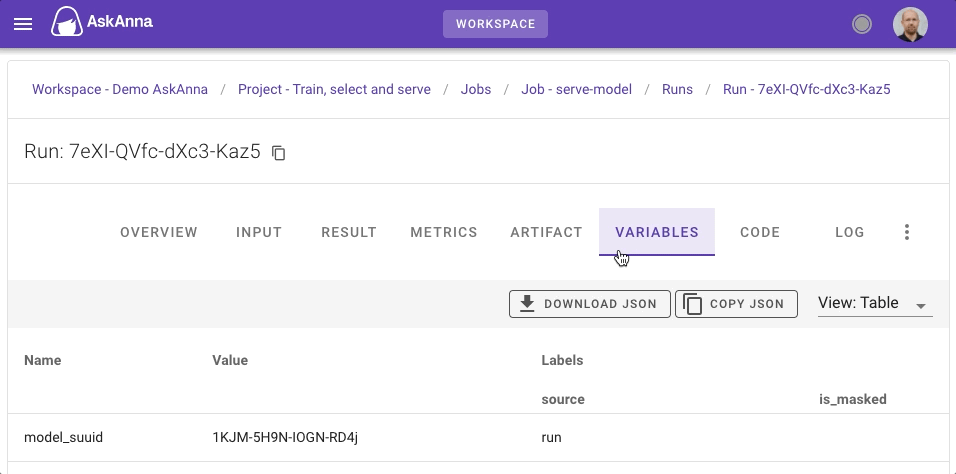
If you want to check the input used to make the prediction, you can find the payload on the INPUT tab. And to make it possible to reproduce results, you also need to know the model used. The SUUID of the run containing the trained model is tracked as a variable of the run.
About the project code
In the project code, you see two files and three directories. If you did not create the project, you can also view the source code on GitLab. Let's go through the code directory by directory, file by file.
data
This directory contains the Wine Quality dataset from P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J.Reis. We use the data to train the model.
input
The input directory has some dummy files that can be used to run the jobs select-best-model and serve-model. More about these jobs in the description of the file askanna.yml.
src
This directory contains the Python functions used to train, select and serve the model.
train.py
Train the model that can predict the quality of wine. For the model, we use ElasticNet from scikit-learn. The model will be trained on the wine-quality.csv from the data directory.
You can run train.py locally from the command line:
python src/train.py ${alpha} ${l1_ratio}
The arguments alpha and l1_ratio are optional. If you don't provide these arguments, the script will use default values 0.5.
The script's output is a model.pkl file containing the trained model to predict the wine quality.
The train.py script also tracks some additional meta-information:
Track metrics in a local run
You also track metrics when you run the script locally. In the standard output you can find the location of the JSON files containing the tracked data. Read more about tracking metrics.
select-best-model.py
This Python script starts multiple train jobs in AskAnna. Because of the relation with the train jobs, you can only run this Python script via the command line if you are connected to the AskAnna platform.
The script checks if a payload is available. If not, it will use the dummy payload dummy-select-model.json from the input directory. For loading the payload data we use:
input_path = os.getenv("AA_PAYLOAD_PATH", "input/dummy-select-model.json")
with open(input_path, "r") as f:
input_data = json.load(f)
parameters = input_data.get("parameters", None)
The first line checks if an environment variable AA_PAYLOAD_PATH is available. When you run a job with a payload, AskAnna creates this variable. If there is no payload, we use the default dummy dataset. The following lines load the JSON data from the file and extract the parameters from it.
Next, the script starts multiple train jobs using the parameters alpha and l1_ratio from the input data. These train jobs run parallel. All SUUIDs of the train runs are stored in a list.
Starting a run via a Python script is done using:
askanna.run.start(job_name="train-model", data=param)
When the train jobs are finished, the script will get the metadata, including metrics and variables from these train runs. The script finds the run with the lowest rmse and selects that run as the best model.
To get the meta data of multiple runs in Python, use:
runs = askanna.run.list(
run_suuid_list=train_runs,
include_metrics=True,
include_variables=True
)
The above code will return a list with runs. Per run you can get the metric value for the RMSE via:
for run in runs:
run_rmse = run.metrics.get("rmse").metric.value
After selecting the best model, the script tracks the SUUID and metrics of this train run.
serve.py
The Python script serve.py does the following. First, from the last run of the job select-best-model it gets the SUUID of the run that is selected as the best model:
runs = askanna.run.list(
job_name="select-best-model",
number_of_results=10,
order_by="-created_at",
include_metrics = True
)
for run in runs:
if run.status == "finished":
train_run_suuid = run.metrics.get("run_suuid").metric.value
askanna.track_variable(name="model_suuid", value=train_run_suuid)
print(f"Selected train run: {train_run_suuid}")
break
Then it loads the result object of the selected train run using pickle:
model_data = askanna.result.get(train_run_suuid)
model = pickle.loads(model_data)
If a payload is available, the script loads the input data. If not, it will load the dummy payload dummy-serve-single.json from the input directory:
input_path = os.getenv("AA_PAYLOAD_PATH", "input/dummy-serve-single.json")
input_data = pd.read_json(input_path)
And it predicts the wine quality using the loaded model and data:
prediction = model.predict(input_data)
Then it saves the prediction to a CSV file:
pd.DataFrame(prediction).to_csv("prediction.csv", header=["MPG"], index_label="index")
This script also tracks:
- Identifier of the used trained model
- Count for input rows
- Count for output rows
requirements.txt
The Python packages that are needed to run the project. If you install the packages in a virtual environment, you can also run the scripts locally.
askanna.yml
In the file askanna.yml we define the jobs to train, select and serve models.
job: train-model
The job train-model is defined as follow:
train-model:
job:
- pip install -r requirements.txt
- python src/train.py ${alpha} ${l1_ratio}
output:
result: model.pkl
The job installs the requirements.txt and then runs the script train.py. Input for this job is optional. When running the job, you can add a JSON payload with the alpha and l1_ratio parameters:
{
"alpha": 0.7,
"l1_ratio": 0.4
}
If you provide the above JSON payload, AskAnna will make alpha and l1_ratio available as a payload variable.
The created model.pkl file is saved as the run's result.
job: select-best-model
This job runs the script that starts multiple train jobs, compares the metrics and selects the best model. The job tracks the best model as a metric. This metric is used by the serve.py script.
The job definition to run the Python script is:
select-best-model:
job:
- python src/select-best-model.py
job: serve-model
The job serve-model first installs the requirements.txt and then runs the script serve.py. As a result, it saves the prediction.csv that is created by the script. The definition for this job:
serve-model:
job:
- pip install -r requirements.txt
- python src/serve.py
output:
result: prediction.csv
If you want to predict the wine quality, you can provide this job with a JSON payload using the template below. This template contains input for two wines, but you are flexible in the number of wines you want to predict at the same time.
{
"fixed acidity": {
"0": 7.0,
"1": 6.3
},
"volatile acidity": {
"0": 0.27,
"1": 0.3
},
"citric acid": {
"0": 0.36,
"1": 0.34
},
"residual sugar": {
"0": 20.7,
"1": 1.6
},
"chlorides": {
"0": 0.045,
"1": 0.049
},
"free sulfur dioxide": {
"0": 45.0,
"1": 14.0
},
"total sulfur dioxide": {
"0": 170.0,
"1": 132.0
},
"density": {
"0": 1.001,
"1": 0.994
},
"pH": {
"0": 3.0,
"1": 3.3
},
"sulphates": {
"0": 0.45,
"1": 0.49
},
"alcohol": {
"0": 8.8,
"1": 9.5
}
}
You can also find an example file dummy-serve-multiple.json in the input directory. This dataset contains 347 different wines.
Summary
With this example, you have seen how you can use a project template to set up a project in AskAnna. In this project, three jobs are configured. With these jobs, you can:
- Train a model with different parameters
- Select the best model by comparing a metric from several train runs
- Serve a prediction using the best model
- Optionally use JSON data as input for a run
You have seen how you can review each job and get the results of a trained model. And how to get the predictions of the wine quality. Also, you have seen how to track metrics and variables.
We hope that you get an idea about the power of AskAnna via this demo and how this platform can help you and your team to collaborate on data science projects. If you have questions or need help starting your first project, don't hesitate to contact us. We love to support you!